
Feature Selection using Recursive Feature Elimination | Machine Learning | Python
- Hackers Realm
- Jul 8, 2023
- 4 min read

Recursive Feature Elimination (RFE) is a feature selection technique used to select the most relevant features from a given dataset. It is an iterative process that ranks and eliminates features based on their importance, typically by training a machine learning model and evaluating the performance after removing each feature.

Recursive Feature Elimination provides a systematic way to select relevant features by iteratively eliminating the least important features based on the model's performance. This technique is particularly useful when dealing with high-dimensional datasets where the number of features is much larger than the number of samples.
You can watch the video-based tutorial with step by step explanation down below.
Load the Dataset
First we will have to load the data. We will be using the same dataset we had used for feature selection using chi square. Click here to see the dataset and the preprocessing performed on it
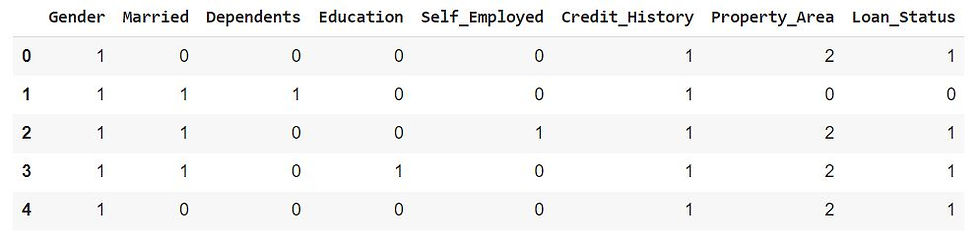
df.head()df.head() is used to display the first few rows of a pandas DataFrame that has been loaded
Import Modules
from sklearn.feature_selection import RFE
from sklearn.tree import DecisionTreeClassifiersklearn.feature_selection - module in scikit-learn provides various methods for feature selection in machine learning tasks. It offers several techniques to help identify and select relevant features from a dataset
sklearn.tree - module in scikit-learn is used for building and working with decision tree-based models
Prepare Data for Feature Selection
Next we will define input and output split
# input split
X = df.drop(columns=['Loan_Status'], axis=1)
y = df['Loan_Status']Drop the column 'Loan_Status' from the DataFrame df and creates a new DataFrame X. The columns parameter specifies the column to be dropped, and axis=1 indicates that the operation should be performed along the columns (features) axis
Then select the column 'Loan_Status' from the DataFrame df and assign it to the variable y. This column is assumed to be the target variable that you want to predict
Fit the model
Next we will have to initialize the Recursive Feature Elimination
rfe = RFE(estimator=DecisionTreeClassifier(), n_features_to_select=3)
rfe.fit(X, y)Creating an instance of the RFE class. The estimator parameter is set to DecisionTreeClassifier(), which will be used to rank and eliminate features. The n_features_to_select parameter is set to 3, indicating that you want to select the top 3 features
Next we will fit the RFE object to the feature matrix X and the target variable y. This will perform the recursive feature elimination process and select the desired number of features based on the estimator's ranking
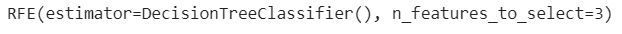
We can see that model has been initialized
Display the Feature Selection Information
Next we will print information about each feature's selection status and ranking based on the Recursive Feature Elimination (RFE) process
for i, col in zip(range(X.shape[1]), X.columns):
print(f"{col} selected={rfe.support_[i]} rank={rfe.ranking_[i]}")range(X.shape[1]) generates a range of numbers from 0 to X.shape[1] - 1, where X.shape[1] represents the number of columns (features) in the feature matrix X. This range will be used as the index for accessing the elements of rfe.support_ and rfe.ranking_
zip(range(X.shape[1]), X.columns) combines the generated range with the column names from X.columns using the zip() function. It creates an iterator that iterates over corresponding elements from the range and the column names simultaneously
for i, col in zip(range(X.shape[1]), X.columns) loop iterates over the pairs of index i and column name col generated by zip(). It allows you to access each feature's index and name simultaneously
Next we will print the information about each feature. It uses f-strings (formatted string literals) to construct the output string. For each feature, it prints the column name col, whether the feature was selected (rfe.support_[i]), and the feature's ranking (rfe.ranking_[i])

We can see that Gender is not selected and rank is 4. Married is not selected and rank is 5. Dependents is also not selected and rank is 3. Self_Employed is not selected as well and rank is 2
We can also see that Education is selected and rank is 1. Credit_History is selected and rank is 1 and Property_Area is also selected and rank is 1 as well
We can infer that all the columns with rank 1 are selected
Final Thoughts
RFE relies on the ranking of features provided by the chosen estimator. It's important to select an appropriate estimator that can accurately rank the features based on their importance or contribution to the prediction task
RFE eliminates features iteratively, starting from the full feature set and removing the least important feature at each iteration. This process continues until the desired number of features or a minimum number of features is reached
It's crucial to evaluate the performance of the model after each iteration of feature elimination. This evaluation helps determine the optimal number of features to retain and ensures that the selected features provide sufficient predictive power
RFE allows flexibility in the choice of the estimator. It can work with various machine learning models, such as decision trees, support vector machines, or logistic regression. The choice of estimator should be based on the specific characteristics of the dataset and the task at hand
RFE can be computationally expensive, especially with large datasets or complex models. It involves training and evaluating the model multiple times, which can be time-consuming. Consider the computational resources available and the trade-off between computational complexity and the benefits of feature selection
RFE is particularly useful when dealing with high-dimensional data, where the number of features is much larger than the number of samples. It helps identify a subset of relevant features, reducing the risk of overfitting and improving the model's performance
Feature selection is a part of the broader machine learning pipeline, and its effectiveness depends on the specific dataset and problem at hand. It's recommended to experiment with different feature selection techniques, including RFE, and compare their impact on the model's performance to make informed decisions regarding feature selection in your machine learning workflows
In this article we have explored how we can perform feature selection using recursive feature elimination. In previous articles we have also explored different methods to perform feature selection.
Get the project notebook from here
Thanks for reading the article!!!
Check out more project videos from the YouTube channel Hackers Realm



Comments